Hashing and Hash Table

Hashing involves converting a fixed-size key to its corresponding value using a hash function, which maps the values based on the key.
Example of a Hash Table
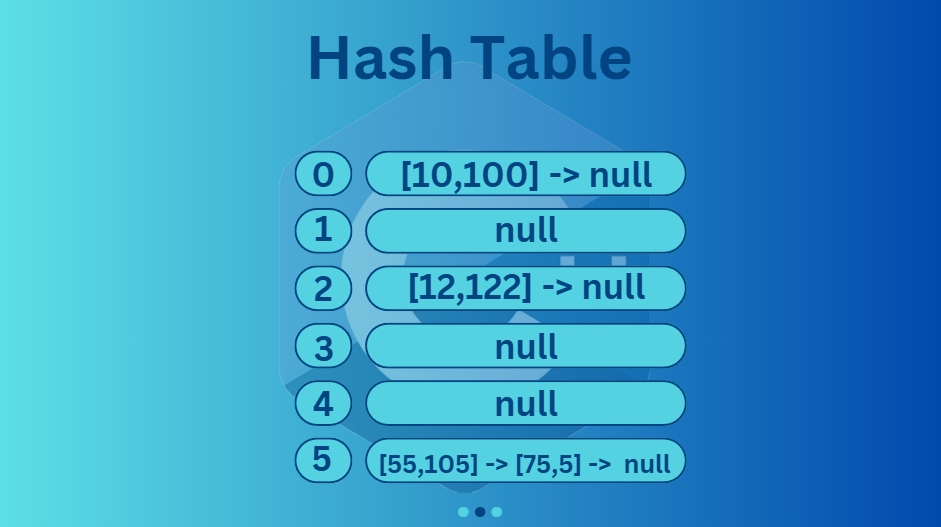
In the image, you can see a hash table, which consists of keys and corresponding values. A `null` value indicates an empty slot or the end of a chain in the table. For example, if the last digit of a number is 0, it is hashed to key 0. If the last digit is 2, it maps to key 2, and so on.
Hash tables are used when you need fast data access. Each data structure has its specific advantages: arrays are fast for searching, linked lists are flexible, and trees allow hierarchical searching. Hash tables provide efficient indexing. For example, in a phonebook, names can be used as keys, and phone numbers as values, similar to a Python dictionary.
Code of a Hash Table
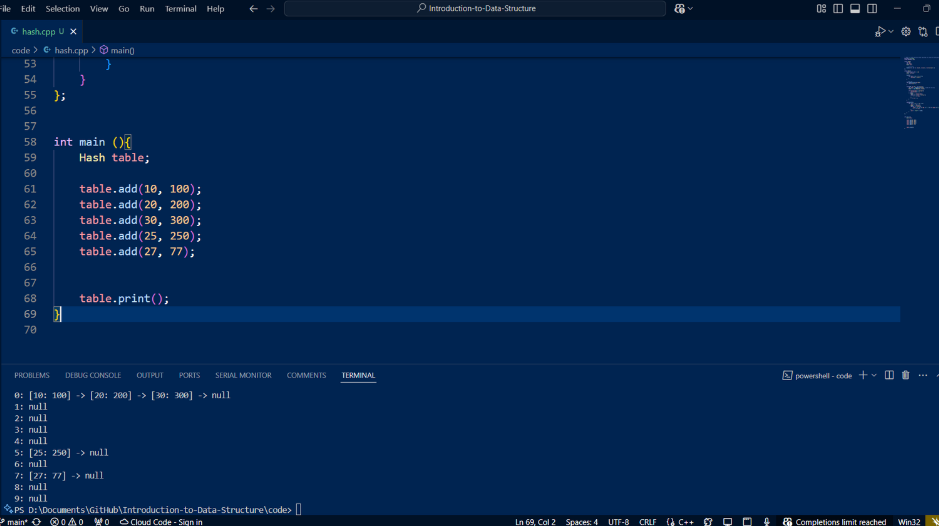
Below is an example code implementing a hash table. It demonstrates adding values, printing the table, and handling keys. The trade-off with hash tables is often between speed and memory usage. Let's go step-by-step:
Step-by-Step Code
// Hash is a data structure that maps keys to values for efficient data retrieval using hash functions.
#include <iostream>
using namespace std;
struct Node {
int key;
int value;
Node* next;
// Constructor
Node(int k, int v) : key(k), value(v), next(nullptr) {}
};
The above code defines a `Node` structure containing an integer key and value, along with a pointer to the next node. This forms the basis of a linked list used for collision handling.
struct Hash {
static const int S = 10;
Node* table[S];
Hash() {
for (int i = 0; i < S; i++) {
table[i] = nullptr;
}
}
};
Here, the `Hash` structure defines the size of the hash table (`S = 10`) and initializes all slots to `nullptr` in the constructor. This sets up the hash table structure.
// Hash function
int hashFunction(int key) {
return key % S;
}
void add(int key, int value) {
int index = hashFunction(key); // Index for the key
Node* n = new Node(key, value);
if (table[index] == nullptr) {
table[index] = n;
} else {
Node* t = table[index];
while (t->next != nullptr) {
t = t->next;
}
t->next = n;
}
}
The hash function maps a key to an index in the hash table using the modulo operator. The `add` function inserts a key-value pair into the table. If there is a collision (i.e., a key hashes to an already occupied slot), it uses chaining (linked list) to store the new value.
void print() {
for (int i = 0; i < S; i++) {
cout << i << ": ";
Node* t = table[i];
while (t != nullptr) {
cout << "[" << t->key << ": " << t->value << "] -> ";
t = t->next;
}
cout << "null" << endl;
}
}
The `print` function iterates over the hash table and prints the keys and values stored at each index. It displays the table in a clear format.
int main() {
Hash table;
table.add(10, 100);
table.add(20, 200);
table.add(30, 300);
table.add(25, 250);
table.add(27, 77);
table.print();
}
Finally, in the `main` function, we create a hash table object, add key-value pairs, and print the table to see the stored values.
So this concludes today’s tutorial. See you in the next one 😊
Check out the full video tutorial:
